
Visual Studio
[DX12] D3D12Multithreading 예제 분석 본문
Microsoft에서 제공하는 DirectX-Graphics-Samples에서 어떻게 Multithreaded Rendering을 구현했는지 분석해보고자 한다.
먼저 프로젝트를 빌드해서 씬이 어떻게 구성되어 있는지 살펴보자.

방이 하나 있고 그 안에 여러가지의 오브젝트들이 배치되어 있으며, 가운데 문어를 담은 수조(?)가 있는 형태의 씬이다.
광원은 여러개이고 수조가 위치한 중심을 기준으로 원을 그리며 돌고 있는 것으로 추정된다.
상하좌우 키를 눌러 카메라를 수조를 중심으로 회전시킬 수 있고, Space로 광원 회전을 Play/Pause 할 수 있다.
프로젝트의 흐름은 DXSample을 상속받은 클래스인 D3D12Multithreading 클래스에서 시작한다.
앞서 언급했던 광원부터 어떻게 구성되어있는지 보자.
D3D12Multithreading::LoadAssets() 함수에서 광원에 대한 정보를 초기화하고 있다.
NumLights는 stdafx.h에 3으로 정의되어 있다.
초기에는 모든 광원이 같은 값을 가지고 시작한다.
이후 D3D12Multithreading::OnUpdate() 함수에서 각 광원마다 위치가 달라지게 되는데, index가 홀수인 광원과 짝수인 광원이 서로 다른 방향으로 회전한다.
Y축을 기준으로 회전하여 Eye, At, Up 벡터를 계산하고, View 행렬을 다시 만들어 저장한다.
이번 예제를 분석하는데 있어 중요한 부분이 아니므로 빠르게 넘어간다.
방과 수조, 상자들을 비롯한 오브젝트들은 어떤 방식을 사용해 배치했을까?
일단 씬 배치를 분석하기 전에 애셋들을 어떻게 로드하는지부터 알아보자.
다시 D3D12Multithreading::LoadAssets() 함수로 돌아간다.
씬 구성을 위한 애셋들을 SampleAssets::DataFileName 경로에서 불러오고 있다. 이 경로는 SquidRoom.h에서 L"SquidRoom.bin"으로 정의하고 있다.
ReadDataFromFile은 단순히 파일을 읽어서 Byte Array로 저장할 뿐이므로 pAssetData가 어떻게 쓰이는지만 추적하면 된다.
이제 본격적인 씬 로드에 들어간다.
Vertex Buffer, Index Buffer, Texture를 순서대로 생성하고 있는데, 먼저 Vertex Buffer를 보자.
pAssetData에 미리 정의된 Offset 만큼 더하여 버텍스 데이터가 위치한 주소를 구하는 로직으로 보아, 각 애셋마다 Offset을 미리 특정 헤더에 정의해놓고 애셋 데이터의 시작 포인터에 더하여 애셋이 실제로 위치한 주소를 구하여 사용하는 방식임을 알 수 있다. 실제로 애셋 로드에 사용되는 Offset들이 SquidRoom.h 파일에 정의되어 있다.
의문인 점은 실제로 그려지는 메시가 여러개임에도 Vertex Buffer는 단 하나만 생성하고 있는 것인데, (바로 다음에 생성하는 Index Buffer도 단 하나만 생성하고 있다) 실제로 Draw Call이 일어나는 D3D12Multithreading::WorkerThread() 함수를 살펴보면 이유를 찾을 수 있다.
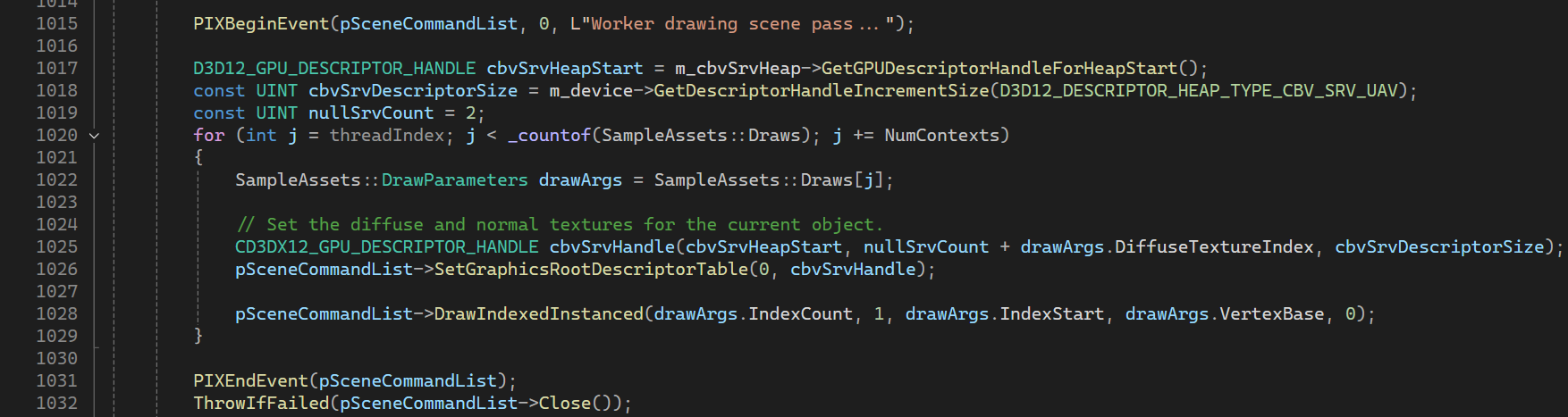
Scene pass의 코드를 보면, (Shadow pass도 마찬가지이므로 어느쪽을 봐도 상관없다) InstanceCount가 1이므로 인스턴싱은 하지 않고 있고, SampleAssets::Draw 배열을 순회하며 DrawIndexInstanced() 함수를 호출하고 있는 것을 볼 수 있다.
여기 사용되는 SampleAssets::Draw 배열은 SquidRoom.h에 아래와 같이 정의되어 있다.
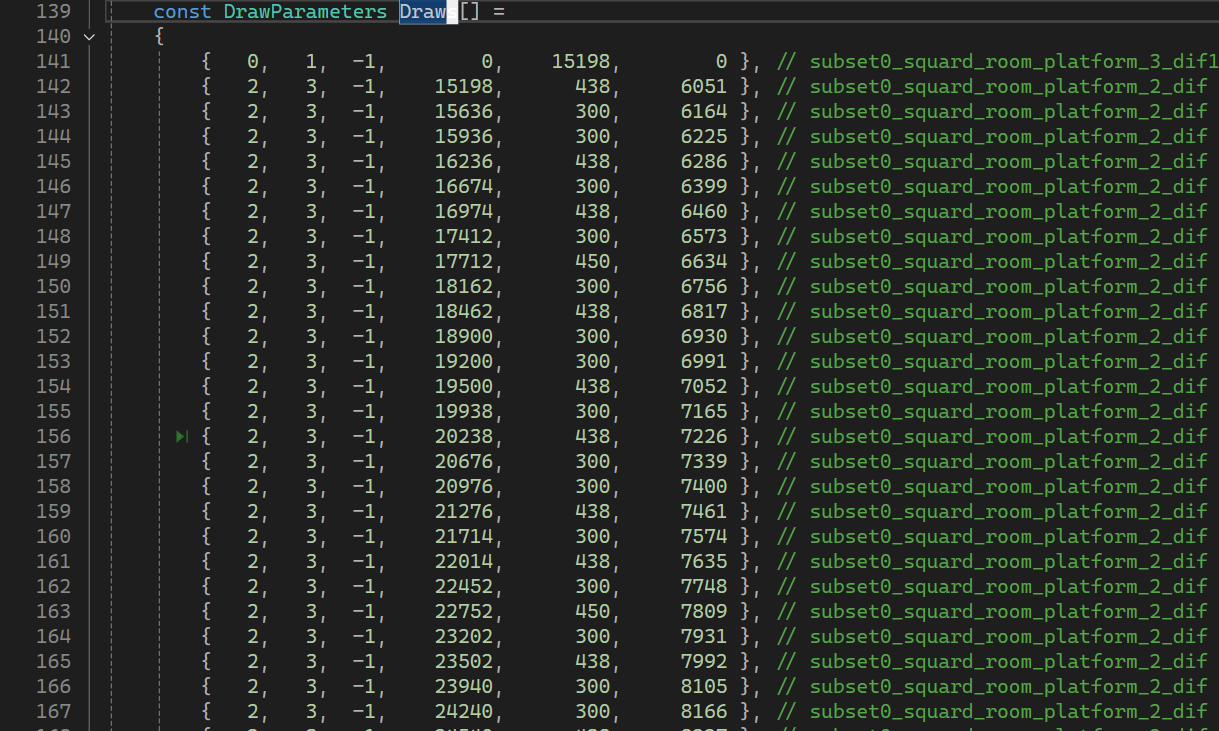
첫번째부터 각각 DiffuseTextureIndex, NormalTextureIndex, SpecularTextureIndex, IndexStart, IndexCount, VertexBase이다. 오브젝트마다 서로 다른 Vertex Data, Index Data, Texture를 사용하여 렌더링할 수 있도록 구성되어 있다.
씬을 잘 살펴보면 같은 종류의 메시가 여러개 배치되어 있는 것을 볼 수 있는데, RenderDoc으로 뜯어보면 버텍스 데이터 자체가 같은 종류의 메시끼리 묶어져 있는 형태로 되어있음을 알 수 있다.
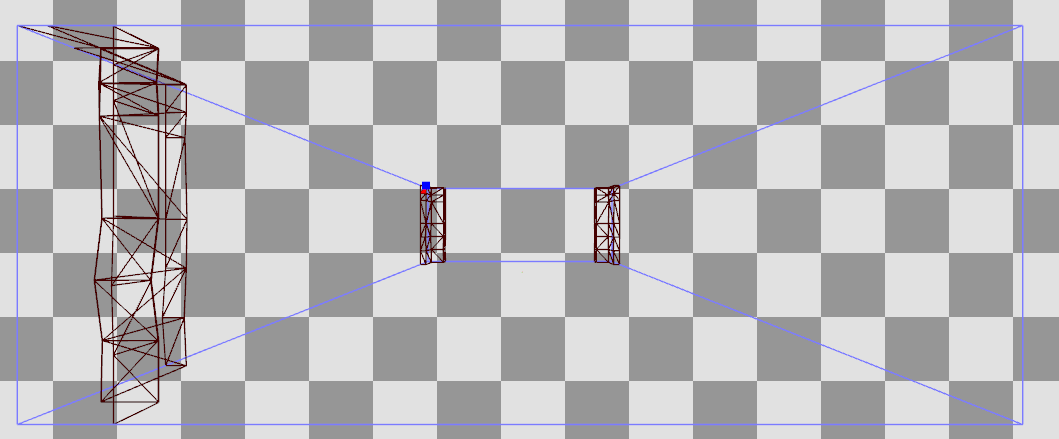

위 이미지는 RenderDoc의 Mesh Viewer로 본 실제 메시의 형태이고, 아래 이미지가 실제로 렌더 타겟에 그려진 이미지이이다. 빨간색 동그라미로 표시된 기둥들이 해당 드로우 콜에서 그려진 메시이다.
인스턴싱을 사용하지 않고 하나의 드로우 콜로 그리기 위해 이러한 방법을 채택한 것으로 보인다. 멀티스레딩에 대한 예제이므로 멀티스레딩과 관련 없는 기능 구현은 최소화하여 학습자가 본 샘플의 주제에 집중할 수 있도록 돕기 위함일까...?
Multithreaded Rendering에 대해 설명하기 전에 마지막으로 FrameResource 클래스에 대해 미리 설명하는 게 좋을것 같다.
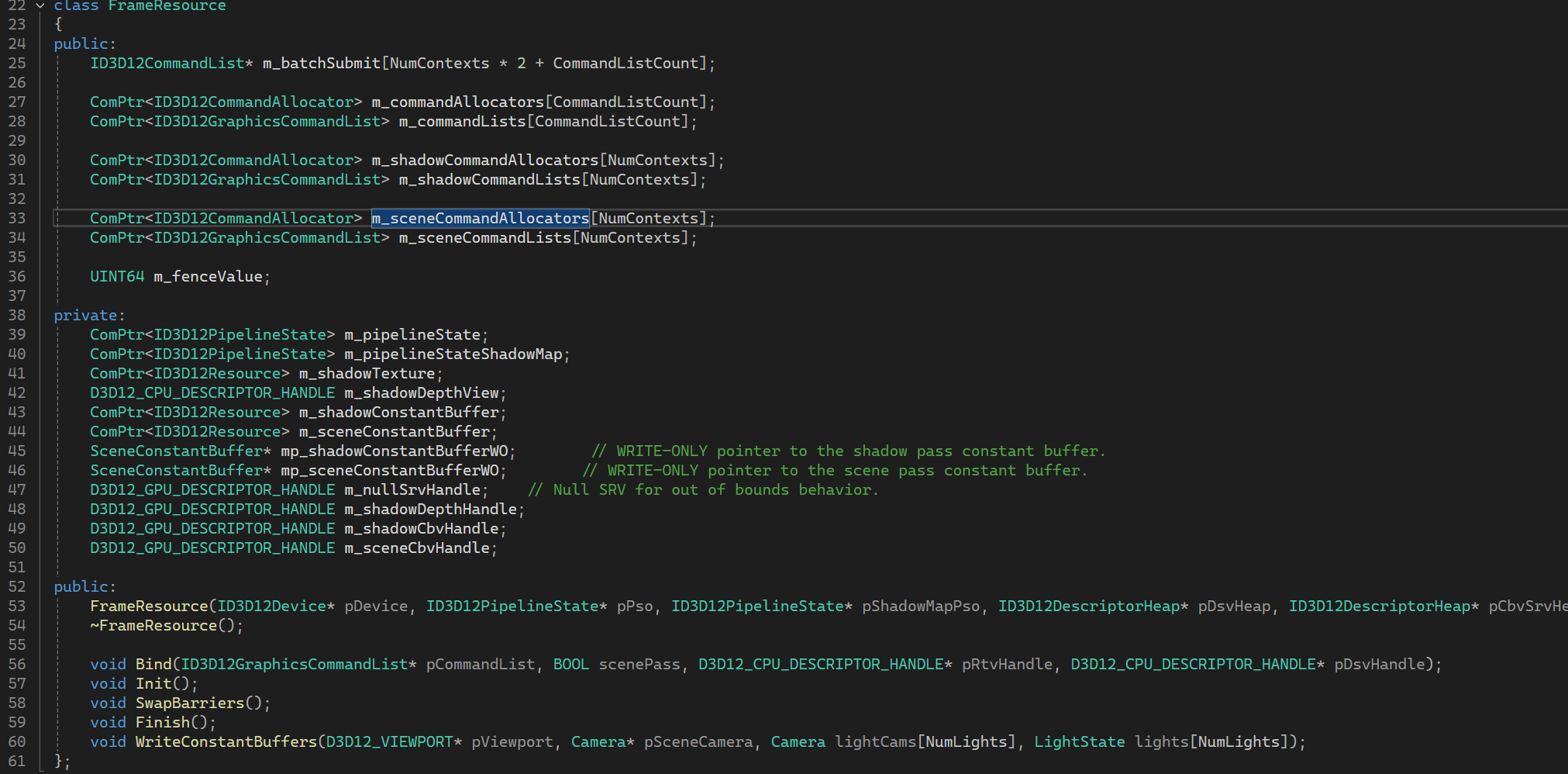
동시에 처리중인 프레임이 여러개인 경우 렌더링에 필요한 정보를 프레임마다 가지고 있어야 한다.
FrameResource는 한 프레임을 렌더링하는데 필요한 모든 객체들을 담고 있다.
여러 객체들이 멤버로 있지만 핵심적으로 알아야 할것은 m_batchSubmit의 크기이다.
NumContexts * 2 + CommandListCount 라고 되어 있는데, NumContexts * 2는 각 쓰레드마다 Shadow Pass, Scene Pass를 위한 Command List 2개씩 가지고 있기 때문이고, CommandListCount는 stdafx.h에 3으로 정의되어 있는데, 메인 쓰레드에서 사용하는 Pre, Mid, Post Command List를 위한 것이다.
각 Command List가 m_batchSubmit 배열에 어떤 순서로 배치되어 있는지도 미리 알아두면 분석에 도움이 될것이다.

FrameResource의 생성자의 맨 마지막 부분이다. 메인 쓰레드에서 사용하는 Pre, Mid Command List가 순서대로 들어가고, 그다음 각 쓰레드의 Shadow Pass에서 사용할 Command List, Scene Pass에서 사용할 Command List를 넣은 뒤, 맨 마지막에 Post Command List가 들어간다.
이제 본격적으로 Multithreaded Rendering을 어떻게 구현했는지에 대해 분석해보자.
멀티 스레딩 관련 로직은 SINGLETHREADED 매크로가 꺼져 있어야 동작하고, stdafx.h에 FALSE로 정의되어 있기 때문에 아무것도 수정하지 않았다면 기본적으로 멀티 스레드로 동작한다.
이번엔 D3D12Multithreading::LoadContexts() 함수에서 출발한다.
NumContexts는 NumLights와 마찬가지로 stdafx.h에 3으로 정의되어 있다.
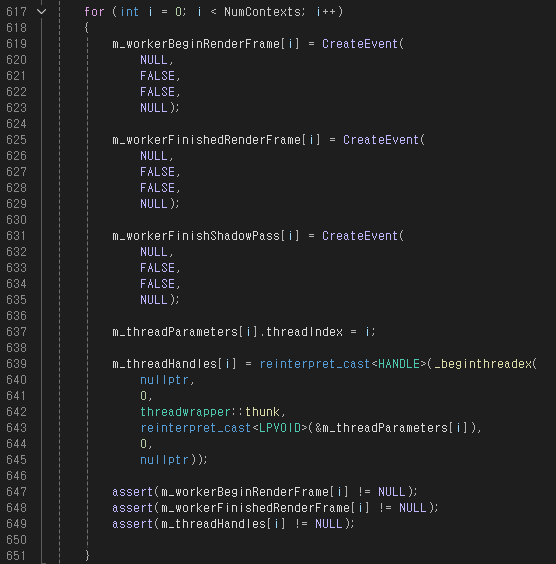
초기화 로직은 쓰레드 동기화에 사용할 이벤트를 생성하는 것에서부터 시작한다.
SetEvent() 함수로 이벤트를 발생시키고, WaitForSingleEvent(), WaitForMultipleObjects() 함수로 이벤트 발생을 기다린다.
렌더링에 사용할 쓰레드를 만들어주는데 __beginthreadex의 세번째 인자인 StartAddress(쓰레드에서 main의 역할을 할 함수의 주소 라고 생각하면 편하다) 에 threadwrapper::thunk() 함수가 들어간다.

thunk 함수 내에서 호출하는 D3D12Multithreading::WorkerThread() 함수가 Multithreaded Rendering의 핵심적인 역할을 하는 함수이다.
이번엔 메인 스레드에서 호출되는 D3D12Multithreading::OnRender() 함수로 가보자.
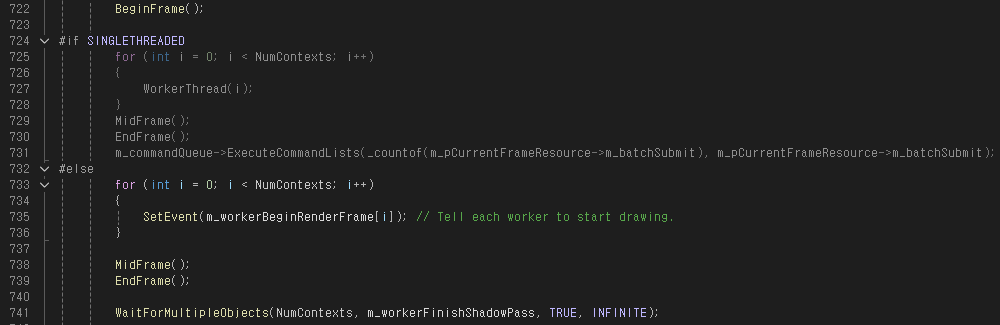
새로운 프레임을 렌더링하기 시작하면 맨 처음 BeginFrame() 함수를 호출한다.
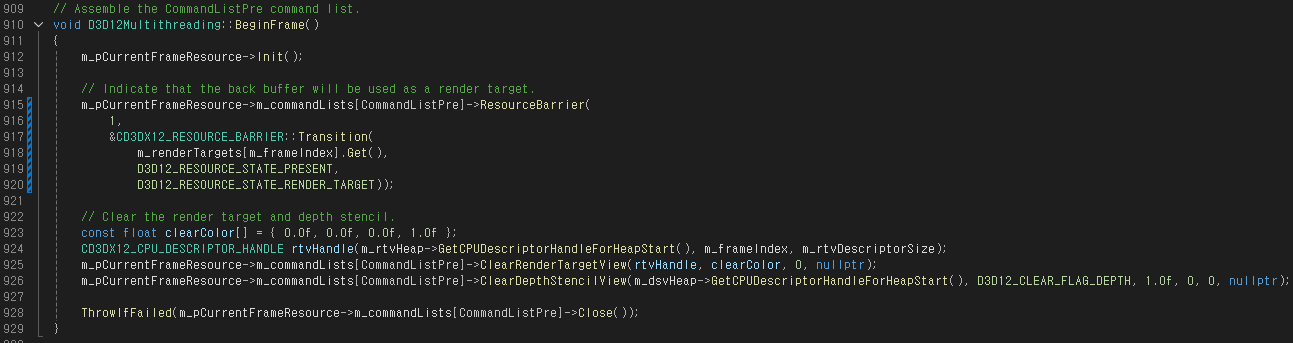
ID3D12GraphicsCommandList::ResourceBarrier() 함수 호출 부분이 너무 길어 추가로 줄바꿈을 하였다.
FrameResource::Init() 함수에서는 이전에 사용했던 렌더링 리소스들을 초기화하는데, 중요하지 않은 부분이라 생략한다.
한 프레임에 대한 모든 렌더링 과정이 끝났을 때 Render Target Resource의 상태가 PRESENT로 변경되었을 것이므로 다시 RENDER_TARGET으로 돌려준다.
Render Target View, Depth Stencil View를 초기화해주고 Command List를 닫는다.

이후 BeginRenderFrame 이벤트를 활성화한다. 이 이벤트는 WorkerThread() 함수의 시작 부분에서 Wait하는데, 잠깐 제쳐두고 MidFrame(), EndFrame() 함수에 대해서 먼저 살펴보자.
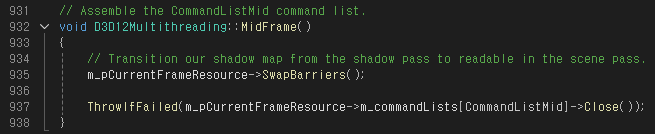
MidFrame() 함수에서는 FrameResource::SwapBarriers() 함수를 호출한다.
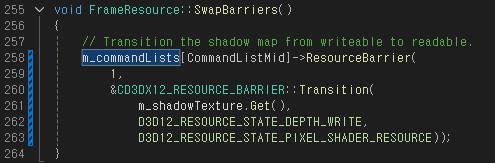
FrameResource::SwapBarriers() 함수에서는 Shadow Texture의 상태를 전환한다. Shadow Pass에서는 Depth Buffer 용도로 사용했지만 Scene Pass에서는 픽셀 쉐이더에서 쓰이는 텍스쳐 리소스여야 하기 때문이다.
SwapBarriers() 함수를 호출하고 BeginFrame()과 마찬가지로 Command List를 닫는다.
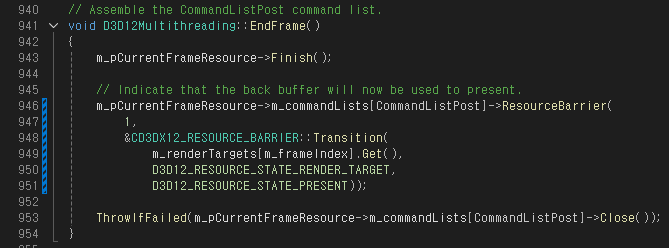
EndFrame() 함수는 사실 두번째 Command List 제출(ID3D12CommandQueue::ExecuteCommandLists() 함수 호출) 이전이라면 언제 호출해도 상관 없는데, 해당 예제에서는 MidFrame() 함수 바로 뒤에 호출하고 있다.
Scene Pass까지 모두 완료된 후 실행되는 Command List를 만든다. FrameResource::Finish() 함수에서는 Shadow Texture의 상태를 PIXEL_SHADER_RESOURCE에서 DEPTH_WRITE로 전환하고, Render Target의 상태를 PRESENT로 변경한다.

이제 Shadow Pass를 위한 작업들을 완료하고 Scene Pass로 넘어갈 준비가 되었으므로 모든 쓰레드가 Shadow Pass에서 사용할 Command List를 만들 때까지 기다린다.
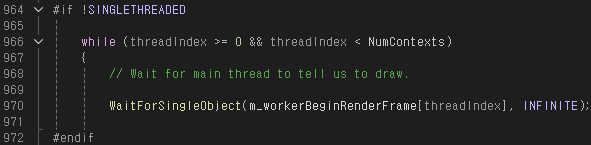
D3D12Multithreading::WorkerThread() 함수로 가보면 인자로 들어오는 threadIndex가 유효할때만 실행되도록 되어 있다.
앞서 언급했던 것처럼 BeginRenderFrame 이벤트가 발생할 때까지 기다린다.
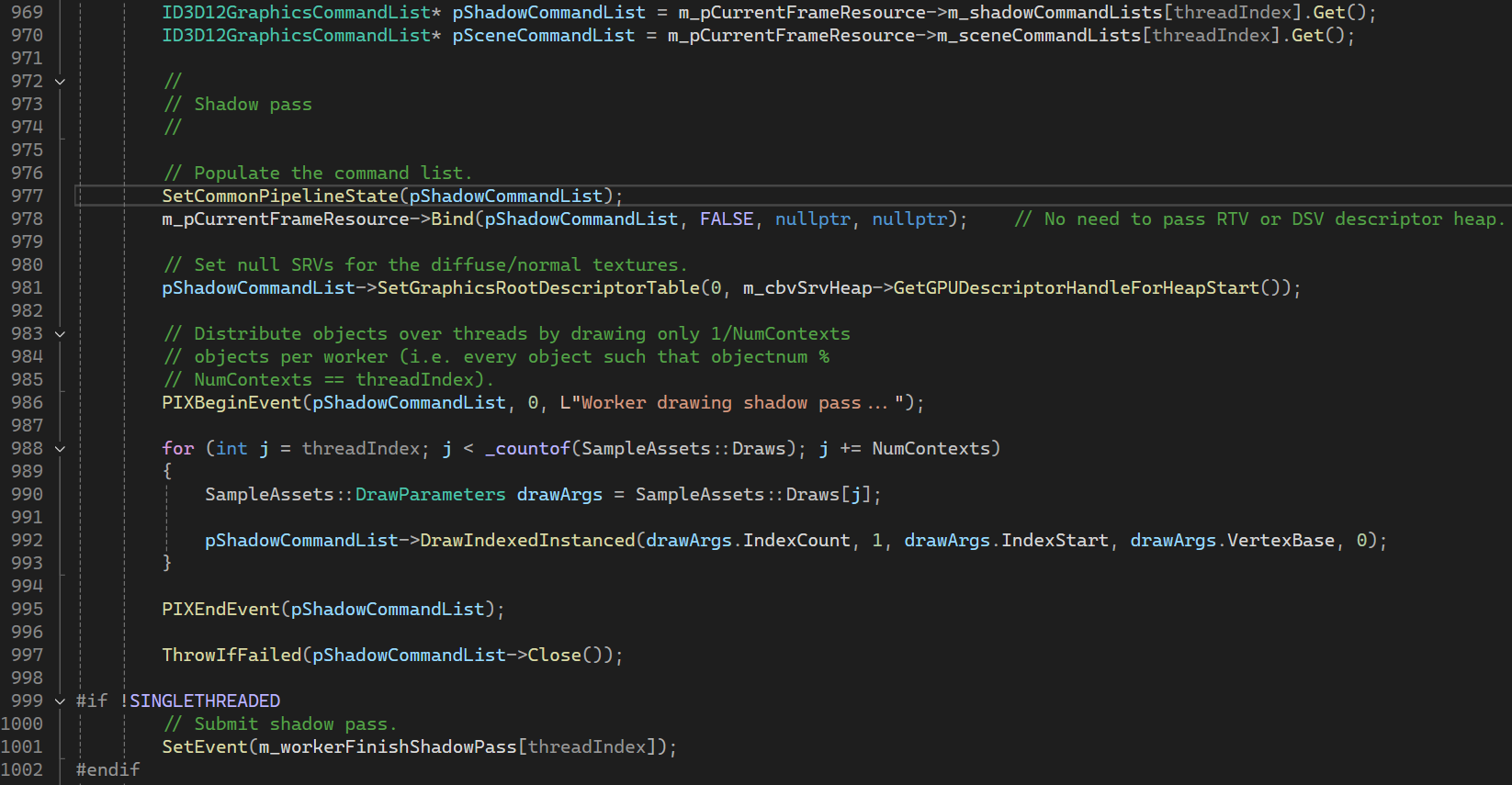
BeginRenderFrame 이벤트가 발생하면 Shadow Pass에서 사용될 Command List를 만든다.
FrameResource에 각 쓰레드를 위한 Command List가 미리 생성되어 있어 자신의 Thread Index로 참조하여 사용한다.
그다음 SetCommonPipelineState() 함수를 호출한다. SetCommandPipelineState()는 Shadow Pass와 Scene Pass에서 공통적으로 해줘야 하는 일들을 수행하는 함수이다.
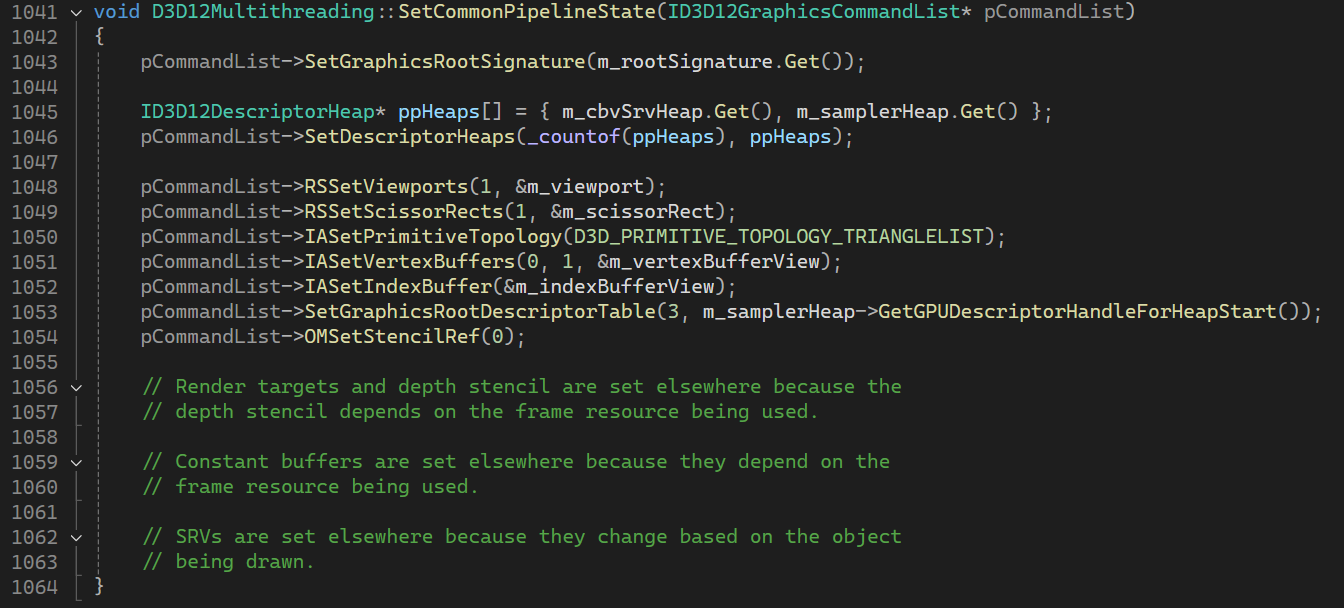
다음 FrameResource::Bind() 함수에서는 Scene Pass와 Shadow Pass의 동작이 달라진다.
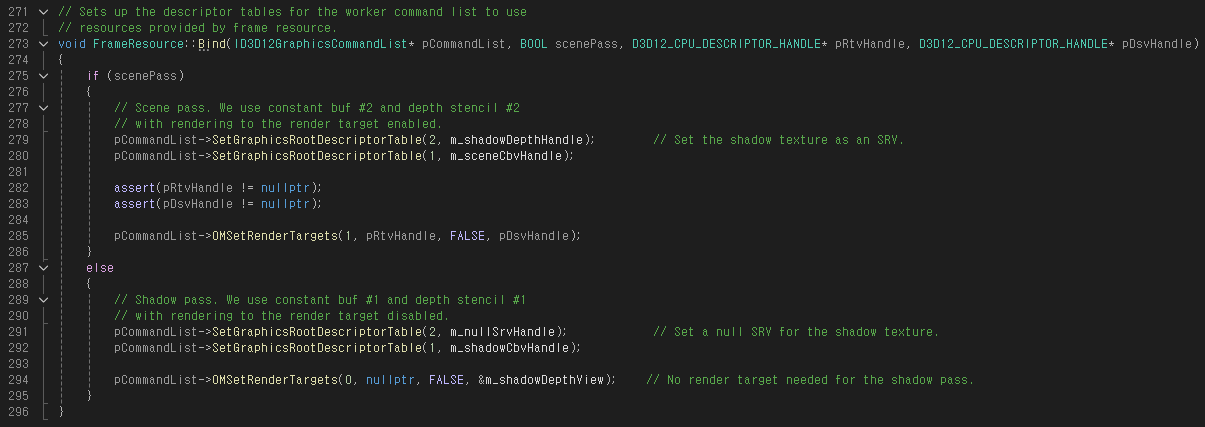
Shadow Pass에서는 픽셀 쉐이더가 어떻게 동작하든 상관 없이 Depth Buffer에 어떤 값이 들어가는지가 중요하기 때문에 필요 없는 디스크립터들은 null resource로 설정한다.
그다음 shadow pass에서는 라이트 기준의 가상의 Camera Space 기준으로 버텍스 위치를 연산하기 때문에 별개의 Constant Buffer를 사용한다.
그다음 Shadow Pass에서는 Render Target은 필요 없고 Depth값을 Shadow Texture에 저장해야 하기 때문에 RenderTarget을 nullptr, Depth Stencil Descriptor를 m_shadowDepthView로 설정한다.

다시 WorkerThread() 함수로 돌아와서 diffuse, normal 텍스쳐 역시 필요 없기에 null resource로 설정한다.

이 작업들이 끝나면 실질적은 Draw Call을 해주게 되는데, 이 예제에서는 전체 메시중 자신의 Thread Index의 배수 인덱스에 위치한 메시에 대해서만 Draw Call을 해주는 것으로 쓰레드간 작업 분담을 구현하고 있다.

Shadow Pass를 위한 모든 작업들이 완료되면 메인 쓰레드에 현재 쓰레드의 Shadow Pass 작업이 끝났음을 알린다.
OnRender() 함수로 돌아가보자.

Shadow Pass까지의 모든 Command List가 만들어졌으므로 Pre, Mid, Shadow Pass 0, Shadow Pass 1, Shadow Pass 2 순서대로 Command List들을 제출한다. Command List를 어떤 순서를 만들었는지와는 상관 없이 인자로 넣은 Command List 배열의 순서에 따라 실행 순서가 결정된다.
이제 메인스레드는 모든 Worker Thread가 Scene Pass에 필요한 Command List를 만들 때까지 기다린다.

Worker Thread로 돌아왔다.
가장 먼저 하는 일은 Shadow Pass에서와 마찬가지로 SetCommonPipelineState() 함수를 호출하는 것이다.
그리고 Shadow Pass때와는 다르게 Render Target View와 Depth Stencil View가 필요하므로 FrameResource::Bind() 함수 호출 시에 인자로 넣어준다. (Bind() 함수에서는 pCommandList->OMSetRenderTargets(1, pRtvHandle, FALSE, pDsvHandle); 로 처리)
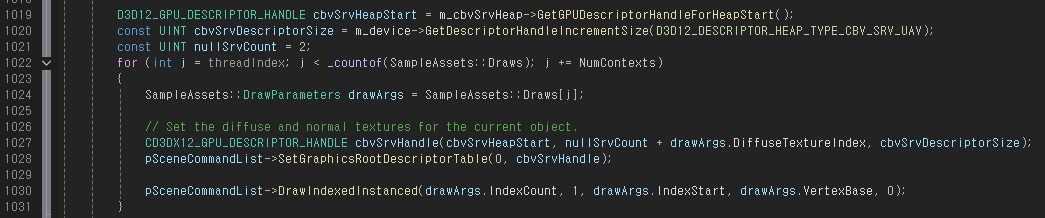
또 Shadow Pass때와는 다르게 Pixel Shader에서 Texture들을 필요로 하므로 null resource가 아닌 실제 텍스쳐 리소스들을 담은 Descriptor Table을 사용한다. 메쉬마다 다른 텍스쳐를 사용하므로 루프마다 Descriptor Table을 설정해준다.
마찬가지로 Thread Index의 배수 인덱스에 존재하는 메쉬에 대해서만 Draw Call을 한다.

Worker Thread에서 해야 하는 모든 작업이 끝났고 메인 쓰레드에 작업이 완료되었음을 알린다.

이부분도 너무 길어서 줄바꿈을 추가로 했다.
앞서 제출했던 5개의 Command List들을 제외하고, Scene Pass 0, Scene Pass 1, Scene Pass 2, Post 총 4개의 Command List들을 제출한다.
퍼포먼스 측정을 위한 코드다. 중요하지 않으므로 넘어간다.
이제 GPU에 렌더 타겟을 디스플레이에 표시하도록 명령하는 IDXGISwapChain3::Present() 함수를 호출한다.
Present() 함수 또한 Command Queue에 명령을 추가하는 방법으로 GPU에 간접적으로 명령을 전달하기 때문에 Present() 함수까지 호출한 뒤 fence의 값을 변경한다.
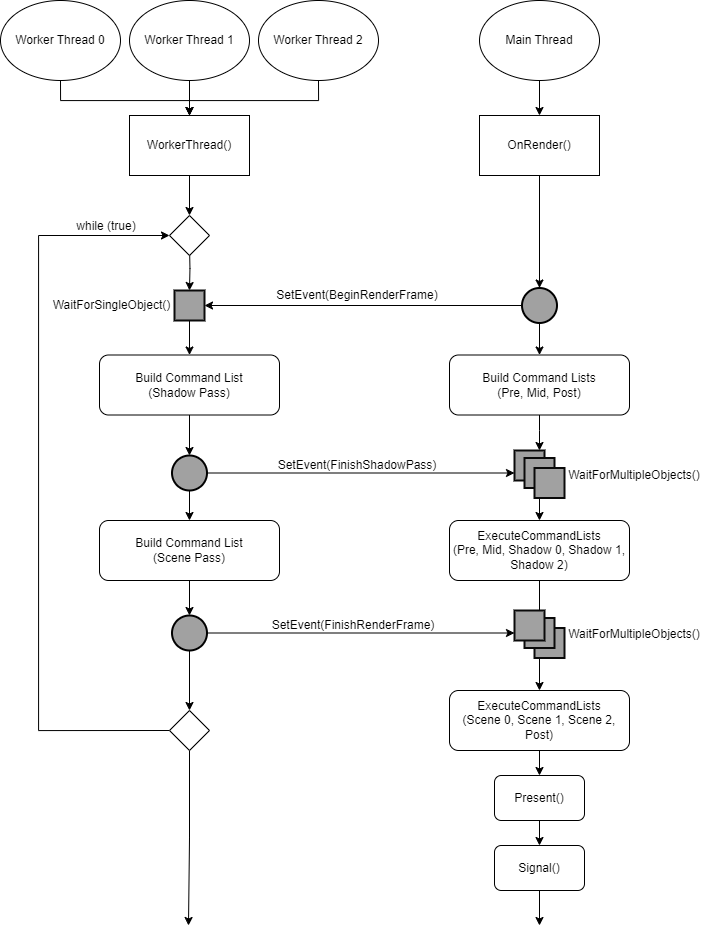
여태까지 살펴보았던 로직을 플로우 차트로 정리해 보면 다음과 같다.
'Graphics' 카테고리의 다른 글
| [Graphics] DX12의 CreateCommittedResource() 와 같은 동작을 Vulkan에서 하려면? (0) | 2024.12.23 |
|---|---|
| [Vulkan] Framebuffer의 재활용에 대하여 (0) | 2024.12.13 |
| [Vulkan] Cubemap Texture 로드시 주의사항들 (0) | 2024.11.18 |
| [Vulkan] Tangent, Bitangent, Normal 시각화 (0) | 2024.11.09 |
| [Vulkan] Instanced Rendering 시에 Instance Buffer와 Storage Buffer의 성능 비교 (0) | 2024.10.23 |

